updated July 2, 2025
CloudBees CI’s High Availability (HA) is the biggest update for Jenkins in a decade. Using this feature:
- You have protection against single points of failure.
- You have access to a high-availability solution for Jenkins.
- One outcome of creating and using controllers running in HA mode in a CloudBees CI cluster positively impacts the cluster’s performance, with significant improvements in the number of build completions.
- You can easily scale up and down to face your workloads.
Controller replicas that work as a single logical controller and a shared file system to synchronize all of them are the basic elements of the underlying architecture providing High Availability (H/A) for CloudBees CI.
One outcome of creating and using controllers running in HA mode in a CloudBees CI cluster positively impacts the cluster’s performance, with significant improvements in the number of build completions.
CloudBees has tested CloudBees CI’s High Availability to back up the performance gain with data and discover possible bottlenecks in the file system shared among all the replicas. This report describes from a high-level perspective the context, terminology, and resources used for those tests, presents the test results, and, in the end, some conclusions to be considered when using CloudBees CI’s High Availability.
Test Environment and Resources for High Availability Evaluation
To test the High Availability (HA) feature, CloudBees has created different load test scenarios using different types of shared file systems.
Tests were performed for 1 hour using the following resources:
- CloudBees CI managed controllers with an initial resource allocation of 4CPU and 16GB.
- Kubernetes agents running on the same cluster for all the builds.
- A Kubernetes cluster with enough capacity to scale the controllers up to 20 or 30 replicas, depending on the test scenario.
- Filestore-NFS (Premium) storage for the GCP (Google Cloud Platform) tests and EBS (Elastic Block Store) and EFS (Elastic File System) storage for the AWS tests.
Testing Methodology for Cloud High Availability Solutions
Testing has been performed in a controlled environment using a self-hosted Git server and multibranch pipelines to generate the workload for the controllers.
The multibranch pipeline used for the testing has the following features:
- 20 parallel stages using the Mock Load Builder plugin.
- An average duration of 2 minutes for the
shsteps inside the mock load block.
The number of controller replicas and the commit frequency on the repositories, triggering the builds for the multibranch pipeline using webhooks, are incrementally raised and scaled.
The commit frequency has been set using multiple tests to find the value where the application serves maximum builds without any performance issues. Over this threshold, the build completion time exceeds the baseline workload reference as the controller can no longer finish a certain number of builds under the expected completion time.
Establishing the Baseline Workload for CI/CD High Availability Testing
The baseline workload has been established as a reference to measure the impact of CloudBees CI’s High Availability (HA). This baseline workload reference is the expected execution time of one build of this multibranch pipeline with normal conditions.
For the tests running on GCP, these are the baseline workload references:
- 2-3 mins. when the non-HA controller uses a network-attached block storage setup.
- 3-4 mins. when the HA controller uses a Filestore-NFS (Premium) shared volume setup with only one replica.
For the tests running on AWS, these are the baseline workload references:
- 2-3 mins. when the controller is a non-HA controller (StatefulSet) using EBS storage.
- 3-4 mins. when the HA controller uses an EFS shared volume setup with only one replica.
The difference between the average duration of 2 minutes for the sh steps inside the mock load block and each baseline workload reference case comes from the time CloudBees CI takes to start and finish the build. Time for tasks like checking out the Pipeline from the repository, writing results and logs, or updating the build status.
The multibranch pipeline creates one commit per branch to trigger builds. Branches are created based on the number of jobs created per hour (Commit frequency). However, no more than 150 branches exist in the repo at any point in time, as we automatically delete the old branches.
Key Metrics to Measure High Availability Software Solutions Performance
Knowing the metrics is essential for understanding any performance report. The list below presents the different metrics we have used to measure the impact of CloudBees CI’s High Availability (HA).
- Commit frequency (commits/minute): The number of commits or new branches per minute in multibranch pipelines. Remember that every commit triggers a new build in the multibranch pipeline.
- Max queue size: The maximum number of builds in the consolidated queue for all the controller replicas.
- Average agents (Pods): The average number of agent pods running concurrently at any given point during the tests.
- Builds completed: How many builds were completed by the controller during each one of the tests.
- Total I/O write MiB/s: Total amount of data written to storage per second.
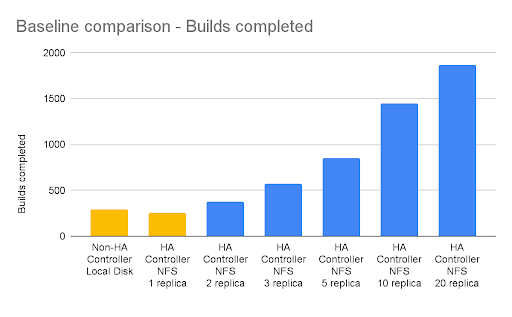
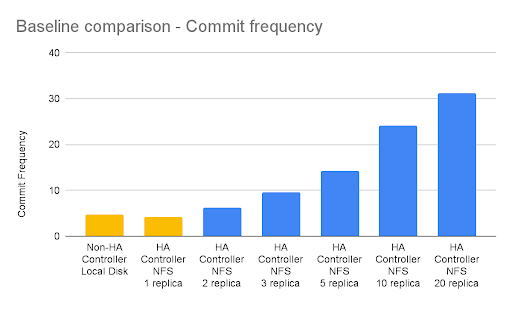
High Availability Tests on Google Cloud Platform (GCP)
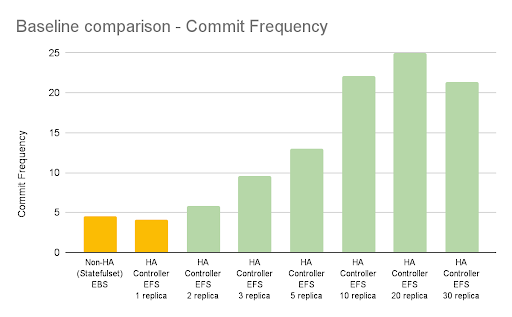
For GCP, the baseline workload references are (in yellow):
- 2-3 mins. when the controller is a non-HA controller using a local volume setup.
- 3-4 mins. when the HA controller uses a Filestore-NFS(Premium) shared volume setup but only one replica.

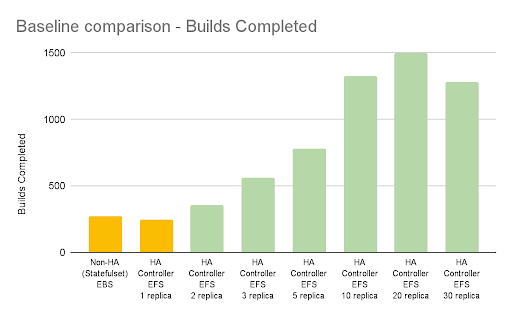
High Availability Performance Testing on AWS Cloud
Tests in AWS have been performed using EKS and the following storage systems.
- EBS for the baseline workload reference.
- EFS shared volume in general-purpose performance mode and Elastic throughput mode.
AWS EFS Elastic Throughput Mode: Impact on High Availability
For AWS, the baseline workload references are (in yellow):
- 2-3 mins. when the controller is a non-HA controller (statefulSet) using EBS storage.
- 3-4 mins. when the HA controller uses an EFS shared volume setup but only one replica.

Detailed Test Results and Raw Data for CloudBees CI High Availability
updated July 2, 2025
Maximizing CI/CD Uptime with CloudBees High Availability Solutions
These tests have been performed in a controlled environment, simulating the workload using multibranch pipelines. CloudBees recommends creating your own testing environment using your own jobs and your company’s selected storage to find the configuration that better fits your company’s needs and budget.
In summary, we can conclude that:
- CloudBees CI’s High Availability (HA) increases your cluster performance by allowing an increment in the commit frequency and, therefore, in the number of builds completed, as the number of replicas grows.
- CloudBees CI’s High Availability (HA) provides scalability as the supported commit frequency and the builds completed grow as the number of replicas grows for a controller running in HA mode. However, this relationship doesn’t follow a linear pattern.
- While the total number of completed builds grows as the number of replicas grows, the average number of completed builds per replica is shown to decrease after a certain number of replicas.
- In the AWS EFS configurations, controllers running in HA mode with more than 20 replicas display a slight regression in scalability. This is because the I/O exceeded what EFS could handle in our configuration.
- According to our tests and setup, CloudBees CI’s High Availability (HA) bottlenecks seem to lie at the file system level. For a large number of replicas, your file system should be able to provide enough throughput to keep up with the data written by all of them.