
 Over the years, Jenkins has become the undisputed ruler among continuous integration (CI), delivery and deployment (CD) tools. It, in a way, defined the CI/CD processes we use today. As a result of its leadership, many other products have tried to overthrow it from its position. Among others, we got Bamboo and Team City attempting to get a piece of the market. At the same time, new products emerged with a service approach (as opposed to on-premise). Some of them are Travis, CircleCI and Shippable. Be that as it may, none managed to get even close to Jenkins' adoption. Today, depending on the source we use, Jenkins holds between 50-70% of the whole CI/CD tools market. The reason behind such a high percentage is its dedication to open source principles set from the very beginning by Kohsuke Kawaguchi . Those same principles were the reason he forked Jenkins from Hudson. The community behind the project, as well as commercial entities behind enterprise versions, are continuously improving the way it works and adding new features and capabilities. They are redefining not only the way Jenkins behaves but also the CI/CD practices in a much broader sense. One of those new features is the Jenkins Pipeline plugin . Before we dive into it, let us take a step back and discuss the reasons that led us to initiate the move away from Freestyle jobs and towards the Pipeline .
Over the years, Jenkins has become the undisputed ruler among continuous integration (CI), delivery and deployment (CD) tools. It, in a way, defined the CI/CD processes we use today. As a result of its leadership, many other products have tried to overthrow it from its position. Among others, we got Bamboo and Team City attempting to get a piece of the market. At the same time, new products emerged with a service approach (as opposed to on-premise). Some of them are Travis, CircleCI and Shippable. Be that as it may, none managed to get even close to Jenkins' adoption. Today, depending on the source we use, Jenkins holds between 50-70% of the whole CI/CD tools market. The reason behind such a high percentage is its dedication to open source principles set from the very beginning by Kohsuke Kawaguchi . Those same principles were the reason he forked Jenkins from Hudson. The community behind the project, as well as commercial entities behind enterprise versions, are continuously improving the way it works and adding new features and capabilities. They are redefining not only the way Jenkins behaves but also the CI/CD practices in a much broader sense. One of those new features is the Jenkins Pipeline plugin . Before we dive into it, let us take a step back and discuss the reasons that led us to initiate the move away from Freestyle jobs and towards the Pipeline .
The Need for Change
Over time, Jenkins, like most other self-hosted CI/CD tools, tends to accumulate a vast number of jobs. Having a lot of them causes quite an increase in maintenance cost. Maintaining ten jobs is easy. It becomes a bit harder (but still bearable) to manage a hundred. When the number of jobs increases to hundreds or even thousands, managing them becomes very tedious and time demanding.
If you are not proficient with Jenkins (or other CI/CD tools) or you do not work for a big project, you might think that hundreds of jobs is excessive. The truth is that such a number is reached over a relatively short period when teams are practicing continuous delivery or deployment. Let's say that an average CD flow has the following set of tasks that should be run on each commit: building, pre-deployment testing, deployment to a staging environment, post-deployment testing and deployment to production. That's five groups of tasks that are often divided into, at least, five separate Jenkins jobs. In reality, there are often more than five jobs for a single CD flow, but let us keep it an optimistic estimate. How many different CD flows does a medium sized company have? With twenty, we are already reaching a three digits number. That's quite a lot of jobs to cope with even though the estimates we used are too optimistic for all but the smallest entities.
Now, imagine that we need to change all those jobs from, let's say, Maven to Gradle. We can choose to start modifying them through the Jenkins UI, but that takes too much time. We can apply changes directly to Jenkins XML files that represent those jobs but that is too complicated and error prone. Besides, unless we write a script that will do the modifications for us, we would probably not save much time with this approach. There are quite a few plugins that can help us to apply changes to multiple jobs at once, but none of them is truly successful (at least among free plugins). They all suffer from one deficiency or another. The problem is not whether we have the tools to perform massive changes to our jobs, but whether jobs are defined in a way that they can be easily maintained.
Besides the sheer number of Jenkins jobs, another critical Jenkins' pain point is centralization. While having everything in one location provides a lot of benefits (visibility, reporting and so on), it also poses quite a few difficulties. Since the emergence of agile methodologies, there's been a huge movement towards self-sufficient teams. Instead of horizontal organization with separate development, testing, infrastructure, operations and other groups, more and more companies are moving (or already moved) towards self-sufficient teams organized vertically. As a result, having one centralized place that defines all the CD flows becomes a liability and often impedes us from splitting teams vertically based on projects. Members of a team should be able to collaborate effectively without too much reliance on other teams or departments. Translated to CD needs, that means that each team should be able to define the deployment flow of the application they are developing.
Finally, Jenkins, like many other tools, relies heavily on its UI. While that is welcome and needed as a way to get a visual overview through dashboards and reports, it is suboptimal as a way to define the delivery and deployment flows. Jenkins originated in an era when it was fashionable to use UIs for everything. If you worked in this industry long enough you probably saw the swarm of tools that rely completely on UIs, drag & drop operations and a lot of forms that should be filled. As a result, we got tools that produce artifacts that cannot be easily stored in a code repository and are hard to reason with when anything but simple operations are to be performed. Things changed since then, and now we know that many things (deployment flow being one of them) are much easier to express through code. That can be observed when, for example, we try to define a complex flow through many Jenkins jobs. When deployment complexity requires conditional executions and some kind of a simple intelligence that depends on results of different steps, chained jobs are truly complicated and often impossible to create.
All things considered, the major pain points Jenkins had until recently are as follows.
- Tendency to create a vast number of jobs
- Relatively hard and costly maintenance
- Centralization of everything
- Lack of powerful and easy ways to specify deployment flow through code
This list is, by no means, unique to Jenkins. Other CI/CD tools have at least one of the same problems or suffer from deficiencies that Jenkins solved a long time ago. Since the focus of this article is Jenkins, I won't dive into a comparison between the CI/CD tools.
Luckily, all those, and many other deficiencies are now a thing of the past. With the emergence of the Pipeline Plugin and many others that were created on top of it, Jenkins entered a new era and proved itself as a dominant player in the CI/CD market. A whole new ecosystem was born, and the door was opened for very exciting possibilities in the future.
Before we dive into the Jenkins Pipeline and the toolset that surrounds it, let us quickly go through the needs of a modern CD flow .
Continuous Delivery or Deployment Flow with Jenkins
When embarking on the CD journey for the first time, newcomers tend to think that the tasks that constitute the flow are straightforward and linear. While that might be true with small projects, in most cases things are much more complicated than that. You might think that the flow consists of building , testing and deployment , and that the approach is linear and follows the all-or-nothing rule. Build invokes testing and testing invokes deployment. If one of them fails, the developer gets a notification, fixes the problem and commits the code that will initiate the repetition of the process.

In most instances, the process is far more complex. There are many tasks to run, and each of them might produce a failure. In some cases, a failure should only stop the process. However, more often than not, some additional logic should be executed as part of the after-failure cleanup. For example, what happens if post-deployment tests fail after a new release was deployed to production? We cannot just stop the flow and declare the build a failure. We might need to revert to the previous release, rollback the proxy, de-register the service and so on. I won't go into many examples of situations that require complex flow with many tasks, conditionals that depend on results, parallel execution and so on. Instead, I'll share a diagram of one of the flows I worked on.
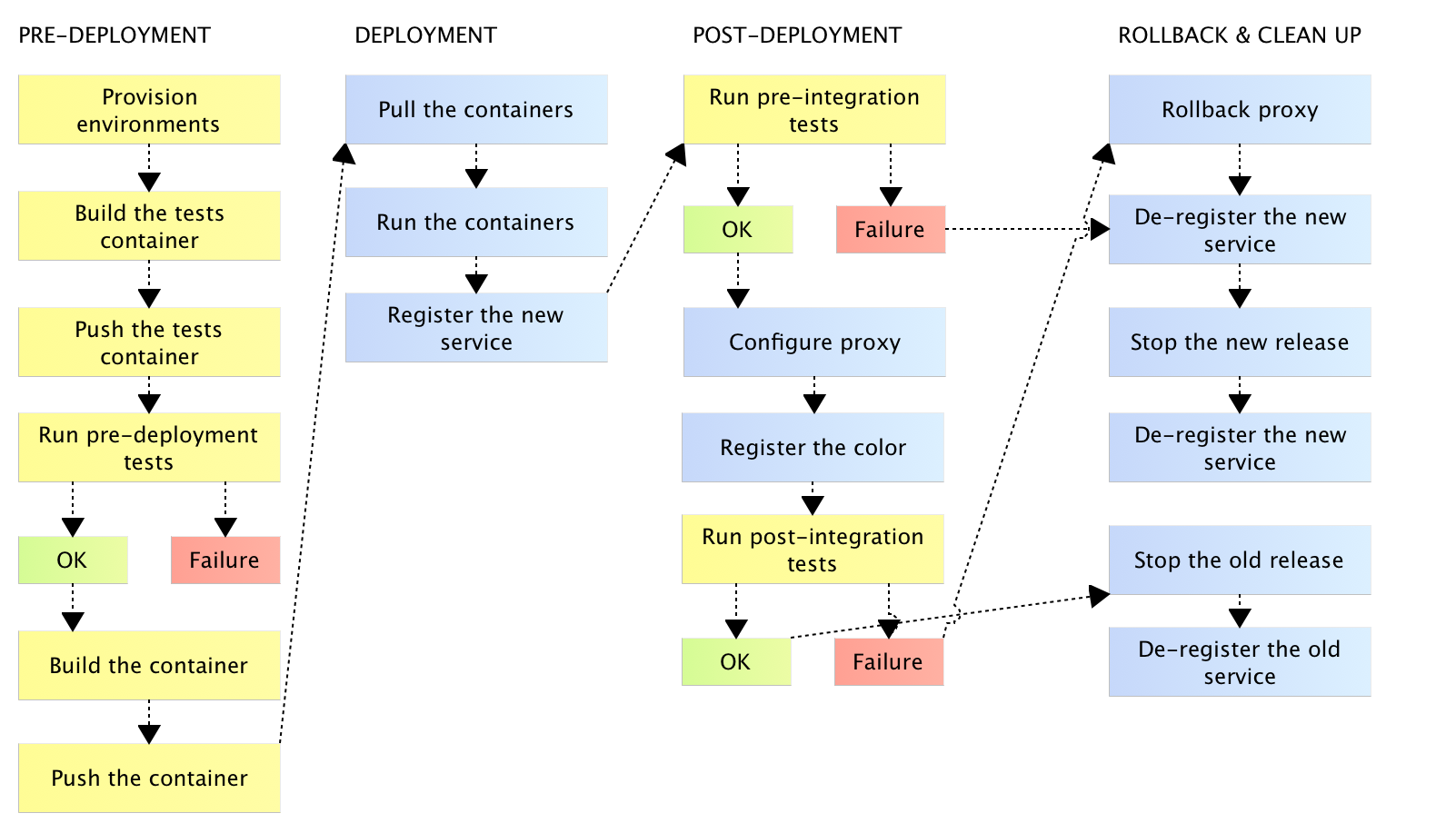
Some tasks are run in one of the testing servers (yellow) while others are run on the production cluster (blue). While any task might produce an error, in some cases such an outcome triggers a separate set of tasks. Some parts of the flow are not linear and depend on task results. Some tasks should be executed in parallel to improve the overall time required to run them. The list goes on and on. Please note that this discussion is not about the best way to execute the deployment flow but only a demonstration that the complexity can be, often, very high and cannot be solved by a simple chaining of Freestyle jobs. Even in cases when such chaining is possible, the maintenance cost tends to be very high.
One of the CD objectives we are unable to solve through chained jobs, or is proved to be difficult to implement, is conditional logic. In many cases, it is not enough to simply chain jobs in a linear fashion. Often, we do not want only to create a job A that, once it's finished running, executes job B, which, in turn, invokes job C. In real-world situations, things are more complicated than that. We want to run some tasks (let's call them job A ), and, depending on the result, invoke jobs B1 or B2 , then run in parallel C1 , C2 and C3 , and, finally, execute job D only when all C jobs are finished successfully. If this were a program or a script, we would have no problem accomplishing something like that, since all modern programming languages allow us to employ conditional logic in a simple and efficient way. Chained Jenkins jobs, created through its UI, pose difficulties to create even a simple conditional logic. Truth be told, some plugins can help us with conditional logic. We have Conditional Build Steps , Parameterised Trigger , Promotions and others. However, one of the major issues with these plugins is configuration. It tends to be scattered across multiple locations, hard to maintain and with little visibility.
Resource allocation needs a careful thought and is, often, more complicated than a simple decision to run a job on a predefined slave. There are cases when slave should be decided dynamically, workspace should be defined during runtime and cleanup depends on a result of some action.
While a continuous deployment process means that the whole pipeline ends with deployment to production, many businesses are not ready for such a goal or have use-cases when it is not appropriate. Any other process with a smaller scope, be it continuous delivery or continuous integration, often requires some human interaction. A step in the pipeline might need someone's confirmation, a failed process might require a manual input about reasons for the failure, and so on. The requirement for human interaction should be an integral part of the pipeline and should allow us to pause, inspect and resume the flow. At least, until we reach the true continuous deployment stage.
The industry is, slowly, moving towards microservices architectures. However, the transformation process might take a long time to be adopted, and even more to be implemented. Until then, we are stuck with monolithic applications that often require a long time for deployment pipelines to be fully executed. It is not uncommon for them to run for a couple of hours, or even days. In such cases, failure of the process, or the whole node the process is running on, should not mean that everything needs to be repeated. We should have a mechanism to continue the flow from defined checkpoints, thus avoiding costly repetition, potential delays and additional costs. That is not to say that long-running deployment flows are appropriate or recommended. A well-designed CD process should run within minutes, if not seconds. However, such a process requires not only the flow to be designed well, but also the architecture of our applications to be changed. Since, in many cases, that does not seem to be a viable option, resumable points of the flow are a time saver.
All those needs, and many others, needed to be addressed in Jenkins if it was to continue being a dominant CI/CD tool. Fortunately, developers behind the project understood those needs and, as a result, we got the Jenkins Pipeline plugin . The future of Jenkins lies in a transition from Freestlyle chained jobs to a single pipeline expressed as code . Modern delivery flows cannot be expressed and easily maintained through UI drag 'n drop features, nor through chained jobs. They can neither be defined through YML (Yet Another Markup Language) definitions proposed by some of the newer tools (which I'm not going to name). We need to go back to code as a primary way to define not only the applications and services we are developing but almost everything else. Many other types of tools adopted that approach, and it was time for us to get that option for CI/CD processes as well.
We'll explore the Jenkins Pipeline plugin in more depth in the next article.
The DevOps 2.0 Toolkit
 If you liked this article, you might be interested in The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices book. (Disclosure: I wrote this book.) Among many other subjects, it explores Jenkins, the Pipeline plugin, and the ecosystem around it in much more detail.
If you liked this article, you might be interested in The DevOps 2.0 Toolkit: Automating the Continuous Deployment Pipeline with Containerized Microservices book. (Disclosure: I wrote this book.) Among many other subjects, it explores Jenkins, the Pipeline plugin, and the ecosystem around it in much more detail.
This book is about different techniques that help us architect software in a better and more efficient way with microservices packed as immutable containers , tested and deployed continuously to servers that are automatically provisioned with configuration management tools. It's about fast, reliable and continuous deployments with zero-downtime and ability to roll-back . It's about scaling to any number of servers, the design of self-healing systems capable of recuperation from both hardware and software failures and about centralized logging and monitoring of the cluster.
In other words, this book envelops the whole microservices development and deployment lifecycle using some of the latest and greatest practices and tools. We'll use Docker, Kubernetes, Ansible, Ubuntu, Docker Swarm and Docker Compose, Consul, etcd , Registrator , confd , Jenkins , and so on. We'll go through many practices and, even more, tools.
The book is available from LeanPub and Amazon (Amazon.com and other worldwide sites).